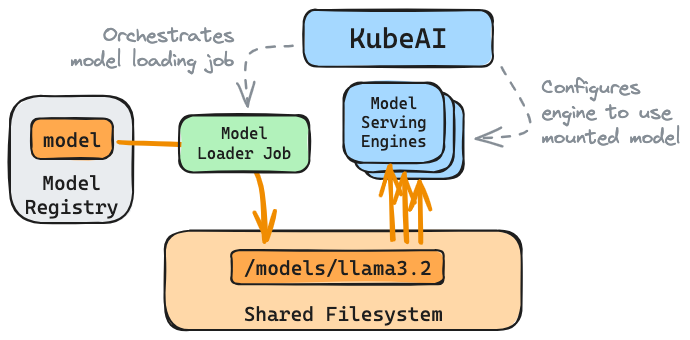
Cache models with GCP Filestore¶
KubeAI can manage model caches. GCP Filestore is supported as a pluggable backend store.
Follow the GKE install guide.
Ensure that the Filestore API is enabled.
gcloud services enable file.googleapis.com
1. Configure KubeAI with Caching Profile¶
You can skip this step if you've already installed KubeAI using the GKE Helm values file: values-gke.yaml.
Configure KubeAI with the Filestore cache profiles.
helm upgrade --install kubeai kubeai/kubeai \
--reuse-values -f - <<EOF
cacheProfiles:
standard-filestore:
sharedFilesystem:
storageClassName: "standard-rwx"
premium-filestore:
sharedFilesystem:
storageClassName: "premium-rwx"
EOF
2. Deploy a model that uses the Filestore Caching Profile¶
Apply a Model with the cache profile set to standard-filestore (defined in the reference GKE Helm values file).
TIP: If you want to use `premium-filestore` you will need to ensure you have quota.
Open the cloud console quotas page: https://console.cloud.google.com/iam-admin/quotas. Make sure your project is selected in the top left.
Ensure that you have at least 2.5Tb of PremiumStorageGbPerRegion quota in the region where your cluster is deployed.

NOTE: If you already installed the models chart, you will need to edit you values file and run helm upgrade.
helm install kubeai-models kubeai/models -f - <<EOF
catalog:
llama-3.1-8b-instruct-fp8-l4:
enabled: true
cacheProfile: standard-filestore
EOF
Wait for the Model to be fully cached. This may take a while if the Filestore instance needs to be created.
kubectl wait --timeout 10m --for=jsonpath='{.status.cache.loaded}'=true model/llama-3.1-8b-instruct-fp8-l4
This model will now be loaded from Filestore when it is served.
Troubleshooting¶
Filestore CSI Driver¶
Ensure that the Filestore CSI driver is enabled by checking for the existance of Kubernetes storage classes. If they are not found, follow the GCP guide for enabling the CSI driver.
kubectl get storageclass standard-rwx premium-rwx
PersistentVolumes¶
Check the PersistentVolumeClaim (that should be created by KubeAI).
kubectl describe pvc shared-model-cache-
Example: Out-of-quota error
Warning ProvisioningFailed 11m (x26 over 21m) filestore.csi.storage.gke.io_gke-50826743a27a4d52bf5b-7fac-9607-vm_b4bdb2ec-b58b-4363-adec-15c270a14066 failed to provision volume with StorageClass "premium-rwx": rpc error: code = ResourceExhausted desc = googleapi: Error 429: Quota limit 'PremiumStorageGbPerRegion' has been exceeded. Limit: 0 in region us-central1.
Details:
[
{
"@type": "type.googleapis.com/google.rpc.QuotaFailure",
"violations": [
{
"description": "Quota 'PremiumStorageGbPerRegion' exhausted. Limit 0 in region us-central1",
"subject": "project:819220466562"
}
]
}
]
Check to see if the PersistentVolume has been fully provisioned.
kubectl get pv
# Find name of corresponding pv...
kubectl describe pv <name>
Model Loading Job¶
Check to see if there is an ongoing model loader Job.
kubectl get jobs