Storage / Caching¶
With "Large" in the name, caching is a critical part of serving LLMs.
The best caching technique may very depending on your environment:
- What cloud features are available?
- Is your cluster deployed in an air-gapped environment?
A. Model built into container¶
Status: Supported
Building a model into a container image can provide a simple way to take advantage of image-related optimizations built into Kubernetes:
-
Relaunching a model server on the same Node that it ran on before will likely be able to reuse the previously pulled image.
-
Secondary boot disks on GKE can be used to avoid needing to pull images.
-
Image streaming on GKE can allow for containers to startup before the entire image is present on the Node.
-
Container images can be pre-installed on Nodes in air-gapped environments (example: k3s airgap installation).
Guides:
B. Model on shared filesystem (read-write-many)¶
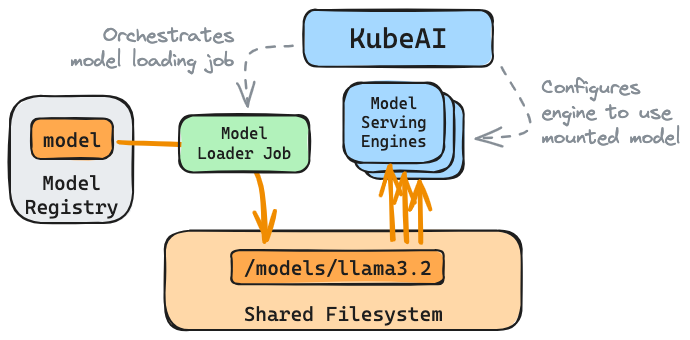
KubeAI can manage model caches on a shared filesystem (i.e. AWS EFS, GCP Filestore, NFS). It manages the full lifecycle of a cached model: loading, serving, and cache eviction (on deletion of the Model).
C. Model on read-only-many disk¶
Status: Planned.
Examples: GCP Hyperdisk ML