Autoscaling¶
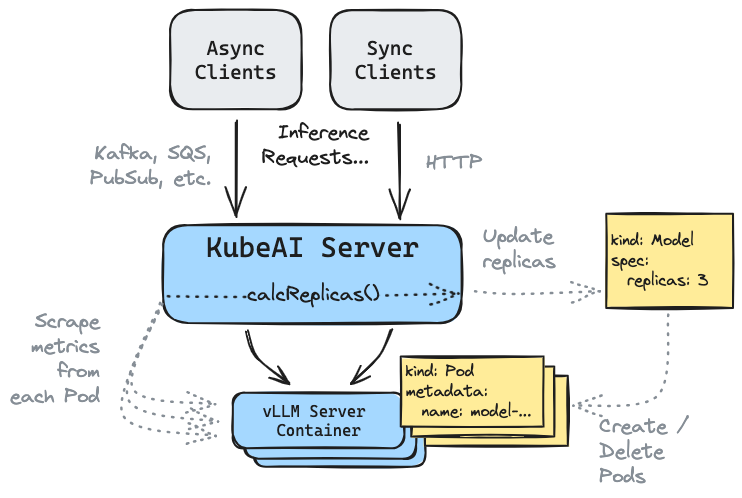
KubeAI proxies HTTP and messaging (i.e. Kafka, etc) requests and messages to models. It will adjust the number Pods serving a given model based on the average active number of requests. If no Pods are running when a request comes in, KubeAI will hold the request, scale up a Pod and forward the request when the Pod is ready. This process happens in a manner that is transparent to the end client (other than the added delay from a cold-start).
Next¶
Read about how to configure autoscaling.