KubeAI: AI Inferencing Operator¶





Deploy and scale machine learning models on Kubernetes.
Built for LLMs, embeddings, reranking and speech-to-text.
Highlights¶
What is it for?
🚀 LLM Inferencing - Operate vLLM and Ollama servers
🎙️ Speech Processing - Transcribe audio with FasterWhisper
🔢 Vector Embeddings - Generate embeddings with Infinity
📚 Reranking - Reorder search results with cross-encoder models
What do you get?
⚡️ Intelligent Scaling - Scale from zero to meet demand
📊 Optimized Routing - Dramatically improves performance at scale (see paper)
💾 Model Caching - Automates downloading & mounting (EFS, etc.)
🧩 Dynamic Adapters - Orchestrates LoRA adapters across replicas
📨 Event Streaming - Integrates with Kafka, PubSub, and more
We strive for an "it justs works" experience:
🔗 OpenAI Compatible - Works with OpenAI client libraries
🛠️ Zero Dependencies - Does not require Istio, Knative, etc.
🖥 Hardware Flexible - Runs on CPU, GPU, or TPU
Quotes from the community:
reusable, well abstracted solution to run LLMs - Mike Ensor, Google
Why KubeAI?¶
Better performance at scale¶
When running multiple replicas of vLLM, the random load balancing strategy built into kube-proxy that backs standard Kubernetes Services performs poorly (TTFT & throughput). This is because vLLM isn't stateless, its performance is heavily influenced by the state of its KV cache.
The KubeAI proxy includes a prefix-aware load balancing strategy that optimizes KV cache utilization - resulting in dramatic improvements to overall system performance.
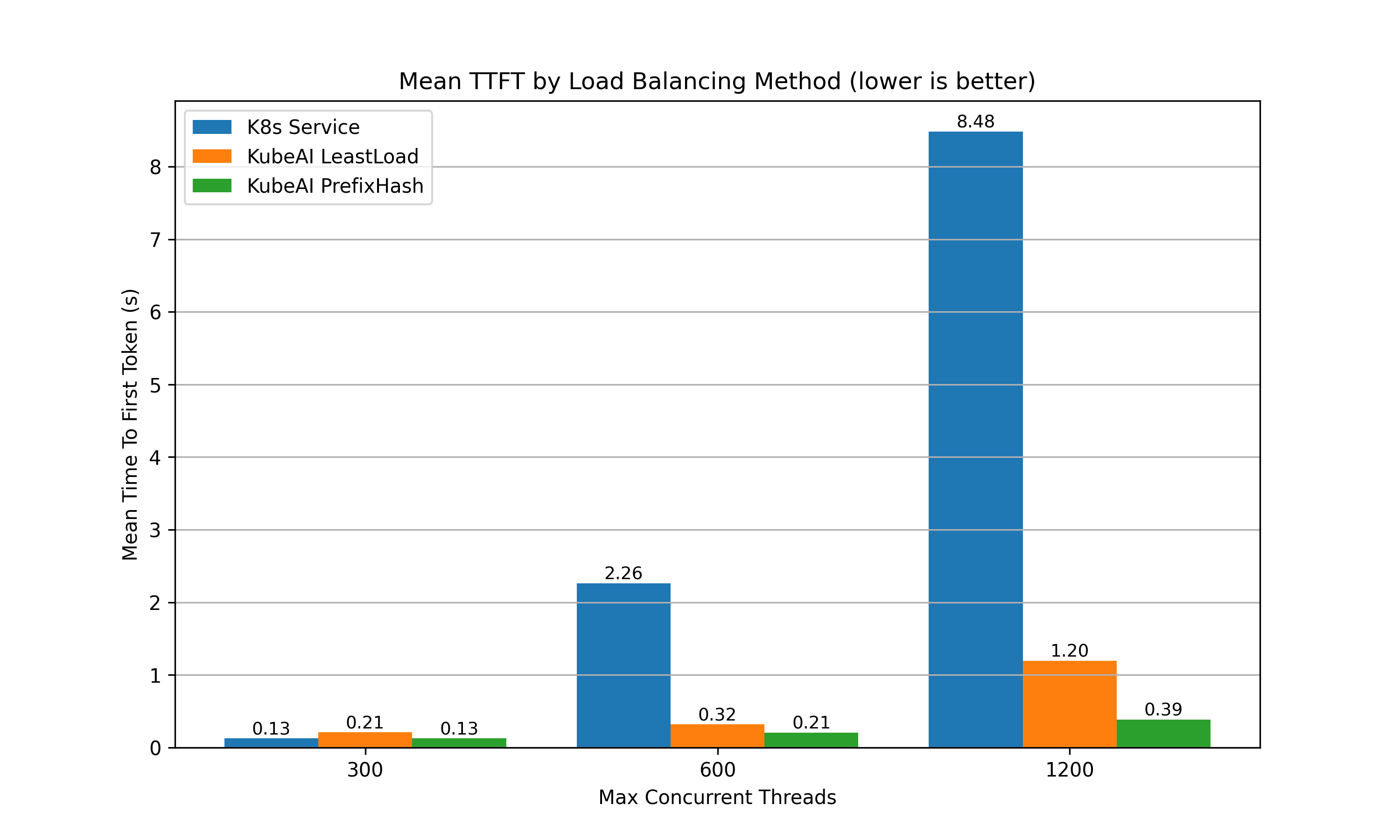
See the full paper for more details.
Simplicity and ease of use¶
KubeAI does not depend on other systems like Istio & Knative (for scale-from-zero), or the Prometheus metrics adapter (for autoscaling). This allows KubeAI to work out of the box in almost any Kubernetes cluster. Day-two operations is greatly simplified as well - don't worry about inter-project version and configuration mismatches.
The project ships with a catalog of popular models, pre-configured for common GPU types. This means you can spend less time tweaking vLLM-specific flags. As we expand, we plan to build out an extensive model optimization pipeline that will ensure you get the most out of your hardware.
OpenAI API Compatibility¶
No need to change your client libraries, KubeAI supports the following endpoints:
/v1/chat/completions
/v1/completions
/v1/embeddings
/v1/rerank
/v1/models
/v1/audio/transcriptions
Architecture¶
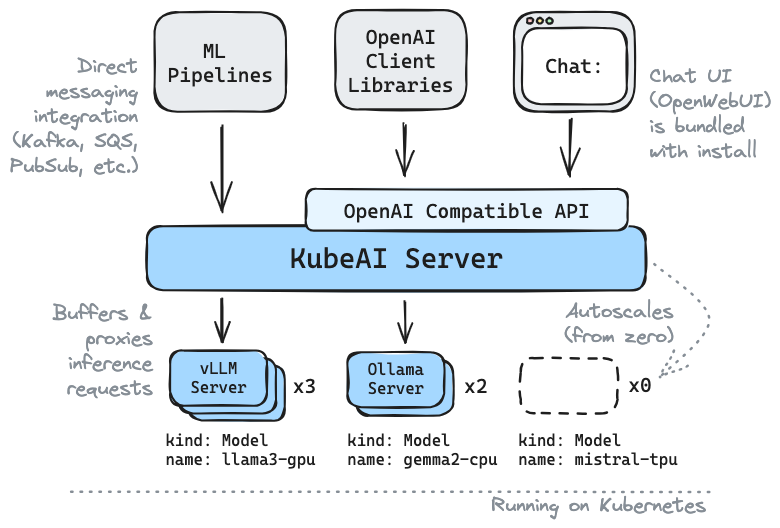
KubeAI consists of two primary sub-components:
1. The model proxy: the KubeAI proxy provides an OpenAI-compatible API. Behind this API, the proxy implements a prefix-aware load balancing strategy that optimizes for KV the cache utilization of the backend serving engines (i.e. vLLM). The proxy also implements request queueing (while the system scales from zero replicas) and request retries (to seamlessly handle bad backends).
2. The model operator: the KubeAI model operator manages backend server Pods directly. It automates common operations such as downloading models, mounting volumes, and loading dynamic LoRA adapters via the KubeAI Model CRD.
Both of these components are co-located in the same deployment, but could be deployed independently.
Adopters¶
List of known adopters:
| Name | Description | Link |
|---|---|---|
| Telescope | Telescope uses KubeAI for multi-region large scale batch LLM inference. | trytelescope.ai |
| Google Cloud Distributed Edge | KubeAI is included as a reference architecture for inferencing at the edge. | LinkedIn, GitLab |
| Lambda | You can try KubeAI on the Lambda AI Developer Cloud. See Lambda's tutorial and video. | Lambda |
| Vultr | KubeAI can be deployed on Vultr Managed Kubernetes using the application marketplace. | Vultr |
| Arcee | Arcee uses KubeAI for multi-region, multi-tenant SLM inference. | Arcee |
| Seeweb | Seeweb leverages KubeAI for direct and client-facing GPU inference workloads. KubeAI can be deployed on any GPU server and SKS | Seeweb |
If you are using KubeAI and would like to be listed as an adopter, please make a PR.
Local Quickstart¶
Create a local cluster using kind or minikube.
TIP: If you are using Podman for kind...
Make sure your Podman machine can use up to 6G of memory (by default it is capped at 2G):# You might need to stop and remove the existing machine:
podman machine stop
podman machine rm
# Init and start a new machine:
podman machine init --memory 6144 --disk-size 120
podman machine start
kind create cluster # OR: minikube start
Add the KubeAI Helm repository.
helm repo add kubeai https://www.kubeai.org
helm repo update
Install KubeAI and wait for all components to be ready (may take a minute).
helm install kubeai kubeai/kubeai --wait --timeout 10m
Install some predefined models.
cat <<EOF > kubeai-models.yaml
catalog:
deepseek-r1-1.5b-cpu:
enabled: true
features: [TextGeneration]
url: 'ollama://deepseek-r1:1.5b'
engine: OLlama
minReplicas: 1
resourceProfile: 'cpu:1'
qwen2-500m-cpu:
enabled: true
nomic-embed-text-cpu:
enabled: true
EOF
helm install kubeai-models kubeai/models \
-f ./kubeai-models.yaml
Before progressing to the next steps, start a watch on Pods in a standalone terminal to see how KubeAI deploys models.
kubectl get pods --watch
Interact with Deepseek R1 1.5b¶
Because we set minReplicas: 1 for the Deepseek model you should see a model Pod already coming up.
Start a local port-forward to the bundled chat UI.
kubectl port-forward svc/open-webui 8000:80
Now open your browser to localhost:8000 and select the Deepseek model to start chatting with.
Scale up Qwen2 from Zero¶
If you go back to the browser and start a chat with Qwen2, you will notice that it will take a while to respond at first. This is because we set minReplicas: 0 for this model and KubeAI needs to spin up a new Pod (you can verify with kubectl get models -oyaml qwen2-500m-cpu).
Get Plugged-In¶
Read about concepts, guides, and API documentation on kubeai.org.
🌟 Don't forget to drop us a star on GitHub and follow the repo to stay up to date!
Let us know about features you are interested in seeing or reach out with questions.
You can also reach the maintainers of this project at: * Slack channel * Discord channel (archived)
Or just reach out on LinkedIn if you want to connect:
Maintainers: